





Bienvenidos a Aula
El martes pasado teníamos la misión de cerrar un planteo que comenzamos a contar durante el segundo teórico: ¿Es posible investigar teniendo en cuenta la gran escala de información a la que nos enfrentamos y producimos a diario? ¿Qué implica investigar utilizando software? Las Humanidades Digitales y la Analítica Cultural, las propuestas metodológicas que les venimos contando desde el encuentro n° 1, se ocupan especialmente de esas preguntas.
Para ilustrar estos nuevos abordajes, invitamos a los participantes del teórico 4 a imaginar el aula como si fuera una plataforma. En esa metáfora, cada uno de las personas que asistimos constituíamos «un dato», y estábamos estructurados según dicha plataforma lo permitía: existía una gran cantidad de datos que estaban dispuestos de una manera ordenada, todos mirando hacia una sección particular; otros teníamos mayor libertad de circulación, pero en general nos encontrábamos en un extremo de la misma y podíamos, desde ese lugar estratégico, «controlar» todo lo que sucedía en ese espacio. Cada uno de estos datos tenía una cantidad de metadatos, es decir algunas etiquetas que ayudaban a describirlos. Esos metadatos están relacionados a su historial como estudiantes y docentes, en los legajos de cada uno de nosotros. Cruzando algún tipo de información (planillas de asistencias y legajos), algunos de los presentes podría acceder a conocer suficiente información sobre cada uno.
Como analistas, el grupo de no-docentes que preparó el teórico planteó una serie de preguntas para ser respondidas por los mismos datos que conforman esta plataforma. Para no tener que preguntarle a cada uno mediante una encuesta y con el fin de poder captar toda la información en un mismo momento se realizó un scraping sonoro: una serie de preguntas que debían ser contestadas realizando chasquidos con los dedos. Para poder datificar esta información, se utilizó una aplicación para medir decibeles (Decibel Ultra). En esta analogía, la aplicación funcionó en términos de API (un software al que podíamos hacerle preguntas para que detectara información de la plataforma que estábamos estudiando).
Las preguntas y sus mediciones fueron los siguientes:
- ¿Quiénes tomaron sólo 1 transporte público para llegar a la facultad? 70,2 decibeles.
- ¿Quiénes tomaron más de un transporte público para llegar a la facultad? 68 decibeles.
- ¿Quiénes trabajan? 70,7 decibeles.
- ¿Quiénes no trabajan? 65 decibeles.
- ¿Quiénes trabajan en blanco? 70 decibeles.
- ¿Quiénes trabajan en negro? 69 decibeles.
- ¿Quiénes trabajan como monotributistas? 60 decibeles.
Luego las analistas instalamos otro software a esta plataforma analógica/imaginada: un software de visualización de información. Apagamos las luces y les pedimos que contesten a nuestras preguntas utilizando las pantallas de sus celulares, mientras sacábamos fotos.
Las preguntas esta vez estuvieron más vinculadas para detectar la distribución de los datos:
- Distribución de los que se sentaron en el mismo lugar que en el teórico anterior.
- Distribución de las mujeres
- Distribución de los hombres
- Distribución de quienes NO nacieron ni en Buenos Aires ni en el Conurbano
Estudio de caso: las desapariciones de Luciano Arruga y Franco Casco
El scraping textual como técnica de investigación
El scraping es una técnica basada y mediada por software utilizada para el procesamiento, el análisis y la interpretación de grandes cantidades de datos culturalmente significativos. En él se extraen de manera automática datos de un sitio web que podremos tratar como información. También se recurren a las APIs (Interfaces de programación de aplicaciones o en inglés, Application Programming Interfaces) que epresentan la capacidad de comunicación entre dos softwares: el que nos brinda la información y el que la recolecta. Con esta metodología de investigación, nos propusimos investigar el discurso mediático y en redes sociales sobre las desapariciones de dós jóvenes en democracia.
Las desapariciones de Luciano Arruga y Franco Casco
El 22 de septiembre del 2008, Luciano Arruga, de dieciséis años de edad, fue detenido de manera ilegal por efectivos del destacamento de Lomas del Mirador. Estuvo allí privado de su libertad unas diez horas, acusado de haber robado un teléfono celular. Durante esa detención Luciano fue torturado y amenazado. Cuatro meses después, el 31 de enero de 2009, salió de su casa y nunca más lo volvieron a ver, sumándose a la lista de “desaparecidos en democracia”.
El cuerpo de Luciano Arruga, tras ser buscado durante cinco años por su familia, apareció en el Cementerio de la Chacarita como “NN”, es decir, cuerpo no identificado. Según el registro, Luciano habría sido atropellado por un auto durante la madrugada del 1º de febrero, a las 3.21 hs., cerca del cruce de la Avenida General Paz y Emilio Castro, en las inmediaciones de la Ciudad Autónoma de Buenos Aires. Luego de ser atropellado, su cuerpo fue llevado al mismo hospital donde había sido buscado por primera vez por su familia. Durante los cinco años que fue buscado, su familia sospechó de la vinculación de su desaparición con la policía.
Paralelamente a la aparición del cuerpo de Luciano comienza la búsqueda de Franco Casco, otro joven de veinte años de edad de la localidad de Florencio Varela, en la zona sur del Conurbano Bonaerense, quien había ido a visitar a su familia en Rosario, Provincia de Santa Fe. En esa localidad, fue detenido el martes 7 de octubre por policías de la comisaría 7°. Luego de veinticuatro días en que no se supo nada de él, su cuerpo sin vida apareció en el río Paraná.
Ambos sucesos se vincularon ya que las víctimas, de corta edad y pertenecientes a sectores marginados de la sociedad, fueron vistas por última vez luego de su detención por parte de la policía y encontradas sin vida en circunstancias que hasta el día de hoy continúan siendo investigadas y juzgadas.
Fases de la Investigación

Fase 1: Problematizar
Como en todo proceso de investigación, el lugar del analista es esencial, ya que él es quien formula las preguntas de investigación y fija sus objetivos. De nada sirve acceder a una gran cantidad de información, por bien estructurada que se encuentre y por más interesante que puedan resultarnos sus números, si no logramos realizar preguntas relevantes y establecer relaciones entre datos. Debido a que estamos explorando esta metodología particular y hemos elegido las técnicas con las que vamos a trabajar, las preguntas de investigación se vuelven cruciales para determinar con qué lentes analizaremos la información relevada, o corpus, y con qué mecanismos procederemos a contestarlas, permitiéndonos andar y desandar los discursos que circularon alrededor de nuestro caso de estudio.
La pregunta de investigación debe ser concisa, alcanzable y relevante. Tiene que estar formulada en un lenguaje sencillo y claro. Es necesario utilizar frases cortas y directas. Es preciso defender la importancia de dedicar una investigación a responder preguntas culturalmente significativas, cuyos resultados de investigación aporten al campo en el que estamos explorando a nivel teórico, empírico y social.
Pregunta problema
¿De qué manera medios de prensa digitales y audiencias participativas de medios sociales construyeron a los actores involucrados en la desaparición de Franco Casco en el contexto de la aparición del cuerpo de Luciano Arruga?
Preguntas específicas
¿Quiénes son los actores que producen las publicaciones? ¿qué se dice de Luciano y de Franco? ¿qué se dice de la policía? ¿qué se omite? ¿en qué medida se diferencian y/o asemejan el relato construido en los medios gráficos del construido colectivamente por los usuarios de la red social Twitter al utilizar los hashtags #lucianoarruga y #francocasco?
Período
1° de octubre hasta el 31 de noviembre de 2014.
Corpus
De mediana escala. Incluye noticias de diferentes medios de prensa digitales argentinos y posts en Twitter (tweets) acerca de dos casos de desaparición de jóvenes en Argentina en años de democracia.
Fase 2: Scrapear
La fase de recolección no se lleva a cabo de forma intuitiva y azarosa, sino que se desprende directamente de la pregunta de investigación. Esta será la brújula que nos indique qué datos necesitamos para cruzar, contrastar y encontrar futuros patrones. Es por eso que debemos llevar a cabo un recorte inicial orientador: ¿en qué sitios nos vamos a centrar? ¿qué período temporal vamos a abarcar? ¿cómo justificamos todas estas decisiones? Todos los datos deben ser almacenados teniendo en cuenta los mismos criterios de búsqueda, por ejemplo: misma fuente, temática, fecha o categoría. Cuanto más rigurosos y detallistas seamos al describir la forma en que armamos la base de datos, más efectivo será nuestro trabajo. Además, el tamiz que utilizamos para recoger la data debe aplicarse de forma homogénea: si nos salteamos datos o dejamos espacios en blanco, será imposible la comparación al momento de visualizar e interpretar. Una vez que tengamos en claro cuáles son los datos que no pueden faltar, llega la hora de buscar aquellas herramientas que nos permitan el acceso a ellos, es decir, las piezas de software que mediarán en nuestro contacto con el objeto de estudio.
Utilizamos los siguientes criterios de selección para construir nuestras bases de datos:
iarios utilizados:
- Los diarios online utilizados fueron La Nación, Clarín, Página/12, La Izquierda Diario y Diario Popular.
- Tomamos todas las notas que aparecieron sobre la temática en el período de tiempo seleccionado.
- Además, agregamos la primera y última nota de cada diario donde se menciona el tema.
- Comparamos las líneas editoriales de los diarios.
- Sólo tomamos textos e imágenes
- Descargamos las notas en archivos PDF, homogéneos, comparables, estructurables.
- Utilizamos las herramientas Readability, Twitter Archiver y Clearly.
- En Twitter tomamos los hashtags #LucianoArruga y #FrancoCasco en el mismo período de tiempo.
- De a información proveída por Twitter Archiver tomamos en cuenta la fecha y hora, los retweets, favoritos, usuarios productores, followers y follows de cada tweet producido.
Fase 3: Estructurar
Una fase importante en el proceso de investigación es la organización de los datos. Una vez recolectados deberemos trabajar en ella de acuerdo a los objetivos planteados. Por lo tanto, mediante su estructuración y procesamiento, convertiremos los datos almacenados en información para nuestra investigación.
Tras el scraping, los datos de una determinada base de datos se encontrarán relacionados en función de cómo estaban organizados en la plataforma de donde extrajimos los datos, gracias a los metadatos: aquellas etiquetas que nos ayudaron a acceder a los lugares del código donde estaban alojados.
Fallas (2013) menciona que la base de datos es como cualquier otra fuente a la que se enfrentan, por ejemplo, los periodistas. Por esa razón es importante tener en cuenta que las mismas siempre son confeccionadas por personas y en ellas puede haber errores involuntarios o deliberados. Como establece el autor, será importante que antes de empezar a trabajar con la información brindada en la base le hagamos ciertas preguntas: ¿quién recopiló los datos y cuáles fueron sus propósitos? ¿qué criterio de recolección se utilizó? ¿qué intereses persigue la persona que entrega la data? ¿ese registro de cifras provee toda la información necesaria para iniciar un proyecto? ¿se deben buscar otras bases o incluso crear las propias?
Una vez finalizada la “entrevista” a nuestra base de datos podremos pasar a su organización ya que la misma no se encontrará estructurada a los propósitos de nuestra investigación. Para ello, un paso muy importante será la “limpieza”, es decir el borrar información que no se relaciona con nuestras preguntas de investigación o nuestros objetivos, debido a que la misma puede dificultar su lectura.
En nuestro caso, la herramienta Readability utilizada para descargar las notas de los diarios online en formato PDF, además borró imágenes, banners y avisos publicitarios de cada una de ellas. Con respecto a Twitter, la herramienta Twitter Archiver proveía muchos datos que no eran relevantes para responder nuestras preguntas de investigación, por lo que eliminamos varias columnas para visibilizar y procesar mejor lo que nos interesaba.
Fase 4: Visualizar
Manovich (2010) define a la visualización de la información como “el mapeo entre los datos discretos y la representación visual”: los significados de la palabra “visualizar” incluyen “hacer visible” y “crear una representación”. Este proceso de visualización se ha modificado a lo largo del tiempo: antes de la existencia del software necesariamente precisaba de un paso anterior que consistía en la cuantificación de los datos para después representarlos gráficamente. En la era de los estudios de software, como hemos visto, podemos resolver ciertos procedimientos a través de distintas aplicaciones, lo que permite cuantificar de forma automática.
También es posible establecer una distinción entre el diseño de la información y la visualización de la información (Manovich, 2010): en el primer caso, el objetivo es reflejar gráficamente datos que ya han sido estructurados; en el segundo, el desafío consiste en descubrir la estructura en la base de datos, desentrañar los patrones que nos permitan obtener respuestas a través de una mirada a gran escala, es decir, se realiza una lectura distante.
En una representación gráfica de la información entran muchos criterios visuales en juego pero el espacio es siempre el prioritario. Otros criterios menos importantes son el tono, color o transparencia para representar distintos datos. Más allá de la sofisticación que puedan presentar muchos gráficos elaborados, la representación gráfica de los fenómenos estudiados siempre conlleva cierto reduccionismo que hay que tener en cuenta.
Estas piezas gráficas que hemos llamado “artefactos” son retomadas por Franco Moretti (2007, p. 79) también bajo la denominación de “objetos artificiales”, entendiendo que son el resultado de un proceso de abstracción y reducción pero que “resultan ser más que la suma de las partes: poseen cualidades emergentes que no eran visibles en el nivel inferior”. De esta manera, se transforman en un recurso fundamental para responder nuestras preguntas de investigación.
Para realizar estas visualizaciones utlizamos las siguientes herramientas:
- Voyant-Tools
- Google Fusion Tables
Fase 5: Interpretar

Agentes y calificativos del hecho


Mediante el análisis de los agentes pudimos reconstruir las líneas editoriales de los diarios, así como ofrecer un contrapunto con un discurso quizá más espontáneo como lo es el de Twitter. Mientras Diario Popular, La Nación y Clarín siguen una postura marcada y similar entre sí, que se vuelca a la mera descripción de los hechos, podemos ver una inclinación de Página/12 a resaltar aspectos de lo político e institucional y su responsabilidad para la resolución de ambos casos. Por otro camino discurre el discurso compartido entre Izquierda Diario y las voces presentes en Twitter, quienes reivindican la militancia y el necesario reclamo de justicia, y polemizan acerca de la participación y responsabilidad policial en ambos crímenes. Las acusaciones hacen referencia a las muy irregulares condiciones en las detenciones de ambos jóvenes, que dan cuenta de un accionar criminal por parte de las fuerzas de seguridad al aprovecharse de la situación de vulnerabilidad y marginalidad de Luciano y Franco. Mediante el análisis de estas voces que se manifiestan en Twitter, en gran medida a través del retweet (que mantiene una marcada similaridad con la lógica del broadcasting), podemos sostener que si bien son en algún grado espontáneas, también reproducen discursos mediáticos ampliamente difundidos, aún proviniendo de un sector popular como La Izquierda Diario.
A la hora de analizar la construcción discursiva de los hechos mediante calificativos en Twitter, a través de los hashtags antes mencionados, también encontramos una continuidad con La Izquierda Diario. En ambos corpus los términos más utilizados son “justicia”, “democratizar”, “humanizar” y “verdad”. Como hemos establecido, tanto en este diario como en esta red social, en el caso de Luciano se puede ver un despliegue del plano simbólico donde su figura se construye como un emblema que hace resurgir la lucha por la memoria, la verdad, la justicia y la democracia.
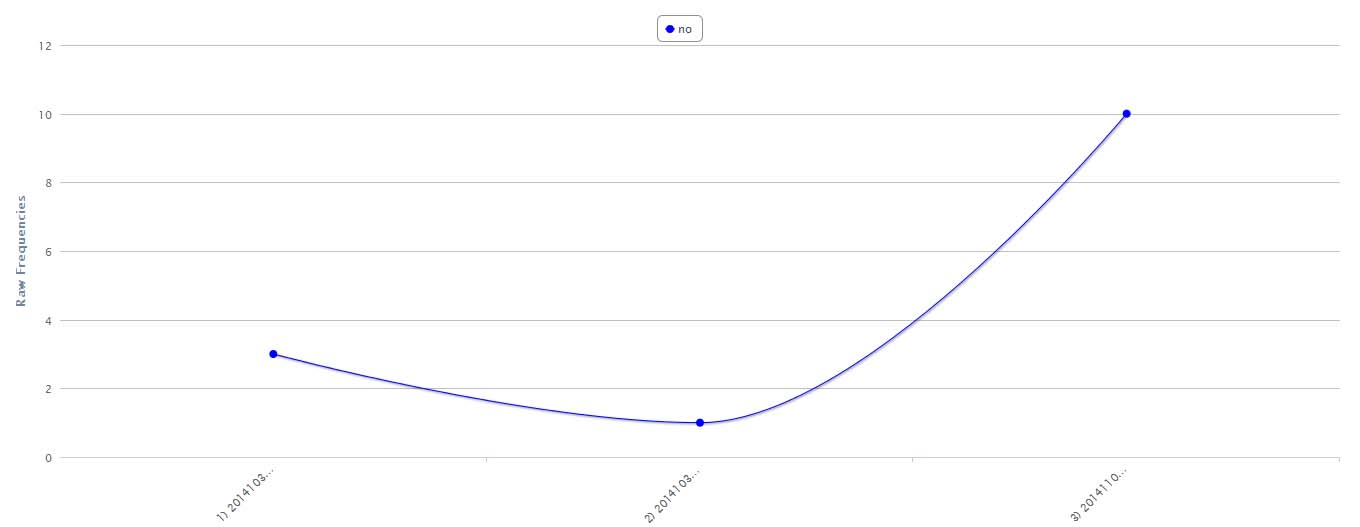
La trayectoria del no

Entre las palabras más mencionadas en las notas periodísticas se encontraba el término «no». Podemos observar que una palabra tan sencilla como esta puede condensar información significativa y valiosa para el estudio discursivo de estos casos y la construcción del relato según diferentes productores mediáticos. En un principio el «no» aparece ligados a un uso cotidiano que refería a la falta de información de los casos («no se encuentra», «no se sabe»), mientras que en una segunda instancia la palabra tomó un cariz que tiene que ver con justicia y la memoria en sentido amplio («no olvidaremos», «que no se repita»). A excepción de La Izquierda Diario que guarda una relación estrecha con los hashtags analizados en Twitter en el sentido que se ancla en la negativa, y en menor medida Página/12; la función reflexiva del “no” escapa del discurso de los otros medios, quienes sólo se centran en el desconocimiento de las circunstancias de cada caso o la denuncia de los organismos gubernamentales que deberían haberlos resuelto.
Los agentes en contexto
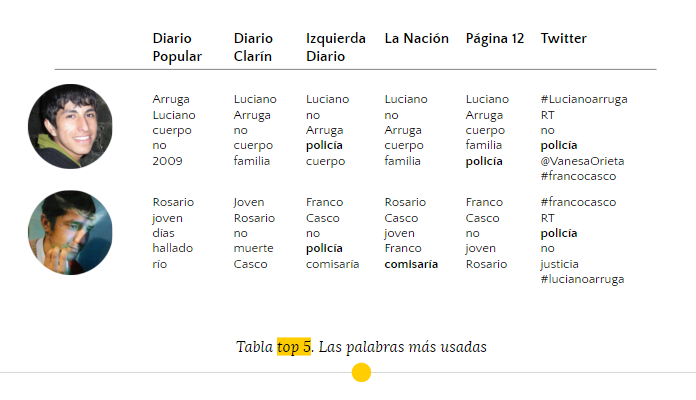
Con el objetivo de no sesgar la interpretación de las palabras que se repiten en el corpus por las categorías en las que nos interesaba analizar, elaboramos una tabla de comparación con las cinco palabras más recurrentes de cada medio analizado.

En el caso de Luciano se observa que en todos los diarios se repite la palabra “cuerpo” y el nombre completo de la víctima. El término “familia” se reitera en Página/12, La Nación y Clarín, mientras que “policía” aparece en La Izquierda Diario, Página/12 y los hashtags estudiados en Twitter. Un caso específico es el de la palabra “no”, que se replica en cuatro de los seis medios analizados. Esta palabra mantiene una relación con el caso de Franco Casco, donde se repite también en cuatro de seis medios (Clarín, Izquierda Diario, Página/12 y Twitter).
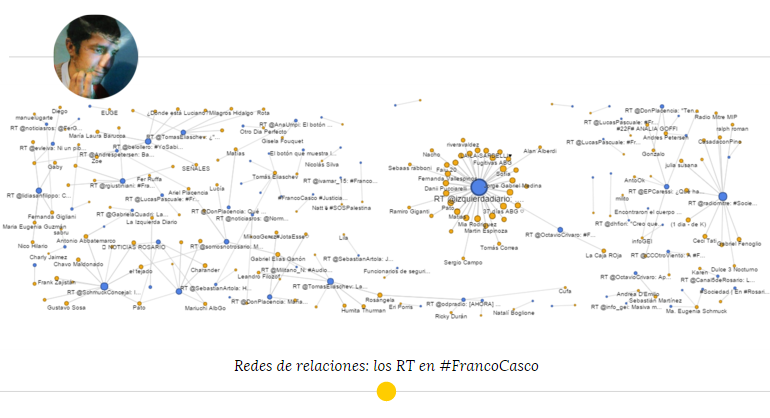
En cuando a Franco, se repite la palabra “joven” y “Rosario” (ciudad donde encontraron su cuerpo) en cuatro diarios, mientras que “policía” solamente aparece en dos diarios y en Twitter. En Twitter se encuentra una interacción entre ambas temáticas, ya que los dos hashtags se referencian entre sí, además de términos que dan cuenta de la lucha y la participación como “justicia” y las menciones al canal de Twitter de la hermana de Luciano, “@vanesaorieta”. También se encontraron en ambos casos la presencia de la sigla RT (retweet), que implica que muchos de los contenidos compartidos en la red social eran reproducciones del contenido de otros usuarios.

Tal como podemos ver en la Tabla «Top 5. Los usuarios más mencionados», los usuarios con mayor cantidad de réplicas son a grandes rasgos de tres tipos: militantes de organizaciones o asociaciones civiles, medios de comunicación o periodistas y políticos. Entre los primeros podemos encontrar a asociaciones en defensa de los derechos humanos como @espacio_memoria e @hijos_capital, pero también de @vanesaorieta y @lucianoarruga que si bien son cuentas de familiares directos de una de las víctimas, se han convertido en referentes en la militancia relacionada a otros casos de desapariciones en democracia. Esto puede inferirse al encontrar menciones de ellos en el caso de Franco Casco, con quien no tienen vínculo familiar directo. Luego, también son replicados y mencionados algunos medios de comunicación como @laizquierdadiario (cuenta oficial de uno de los diarios analizados), @radiomitre o periodistas como @TomasEliaschev. Por último, dentro de los mensajes más retuiteados también encontramos a los de actores políticos como @ProyeNac, la cuenta del proyecto del vicegobernador de la Pcia. de Buenos Aires, Gabriel Mariotto, y @SchmuckConcejal, la cuenta de una concejal de la ciudad de Rosario, por el partido Unión Cívica Radical.
¿El fin del broadcasting?
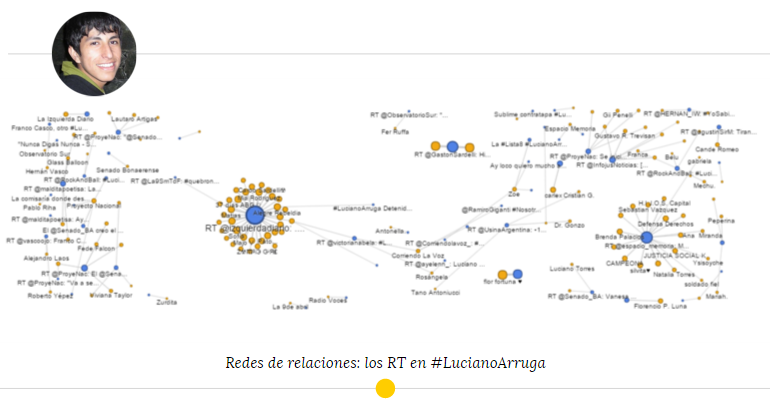
Si relacionamos los usuarios que publicaron usando los hashtags #LucianoArruga y #FrancoCasco y el contenido de su tweet podemos dar cuenta, nuevamente, de la importancia del retweet en las conversaciones propias de la red social Twitter. A primera vista, revisando las nube de palabras, encontramos que “RT” (retweet) se encuentra entre las 10 palabras más frecuentes y que pocas veces se deja de mencionar a lo largo de todo el corpus.
Gracias a esto podemos dar cuenta en ambas conversaciones cómo diferentes usuarios replicaron el mismo mensaje que había escrito otro usuario. La red de relaciones resultó una herramienta sumamente útil para profundizar en este aspecto.
Si bien encontramos algunos contenidos originales y algunos pequeños nodos por fuera del gran nodo principal (un tweet replicado muchas veces), lo que podemos interpretar es que aún en una red social, donde la libertad de construcción de un relato por parte de los usuarios es mayor que en los diarios (ya sean digitales o no), en lugar de elaborar contenido propio, los usuarios deciden dedicarse, en la mayoría de los casos, a replicar contenido ya existente. Esto nos habla, al menos en algunos casos como el que estamos planteando, que la organización de las conversaciones no es del todo descentralizada: líderes de opinión o personas relevantes para un determinado tema monopolizan lo que se dice y cómo se dice.


Las fases de visualización e interpretación no siempre se suceden de forma cronológica. El primer paso es observar qué agrupaciones o conclusiones curiosas nos devuelven los gráficos. Sin embargo, podemos descubrir que no utilizamos el artefacto correcto o que es necesario cruzar nuevos elementos, por lo que volveremos al escalón anterior para continuar el proceso.
Nuevos abordajes
La confección de un corpus mediático en la forma de una base de datos que es plausible de ser mensurada y analizada nos abre una nueva manera de leer. A partir de la elaboración de visualizaciones, guiadas por distintas preguntas de investigación, podemos hallar patrones significativos en cuanto a cómo se construye sentido sobre un determinado tema y cuáles son las especificidades de cada medio que lo aborda. Con este análisis, observamos el carácter profundamente reflexivo y de reclamo que asumen los discursos producidos en algunos medios, mientras que en otros se abstienen de incitar preguntas acerca de la verdad de lo acontecido a ambos jóvenes y sus implicancias políticas, éticas, morales y sociales. Puede consultarse un análisis más detallado de cada una de las visualizaciones ingresando al artículo completo.
Referencias
Fallas, H. (2013). “Entrevista con una base de datos” en VV.AA Manual de Periodismo de Datos Iberoamericano. HIVOS, International Center for Journalists (ICFJ), y Escuela de Periodismo de la Universidad Alberto Hurtado de Chile. Recuperado de http://manual.periodismodedatos.org/hassel-fallas.php
Manovich, L. (2010). “What is a visualization?”. Recuperado de http://manovich.net/content/04-projects/064-what-is-visualization/61_article_2010.pdf
Moretti, F. (2007). La literatura vista desde lejos. Barcelona: Editorial Marbot
Bases de datos:
Tweets #LucianoArruga: http://cor.to/TweetsArruga
Tweets #FrancoCasco: http://cor.to/TweetsCasco
Corpus de noticias sobre Luciano Arruga: http://cor.to/NoticiasArruga
Copus de noticias sobre Franco Casco: http://cor.to/NoticiasCasco
Herramientas utilizadas para el análisis
Google Trends: https://www.google.com.ar/trends
PageOneX: http://www.pageonex.com
Voyant Tools: http://voyant-tools.org/
Google Fusion Tables: https://www.google.com/fusiontables/
Readability: https://www.readability.com/apps
Comentarios