Por Aníbal Rossi

Una imagen que vale 500.00 millones de palabras*
Alguna vez
Séneca supo decir que el andar entre muchos libros disipaba el espíritu. Claro que sus discursos cobraban vida a partir de una positividad muy diferente a la de nuestra contemporaneidad, y aunque aún hoy hablando de
infoxicación y otros hastíos convocamos resonancias antiguas, nuestras disipaciones emergen de un
a priori histórico (
Foucault, 1970) muy distinto que el que habitaba el autor de aquella máxima.
A tal punto que lo que hasta hace poco tiempo seguía siendo una verdad universal, hoy se resignifica. Con estrategias de lectura como la distante (distant reading)
propuesta por Moretti y la asistencia de potentísimos algoritmos capaces de leer y devolvernos fenómenos invisibles para el ojo del lector humano (
reading machines). Diríamos que
más que disipar el espíritu también es capaz de cultivarlo.
Del mismo modo una imagen ya no sólo puede valer más que mil palabras, como versaba el viejo aforismo, sino que también puede ser
el equivalente de 500.000 millones de palabras como es el caso de los gráficos devueltos por
N-gram cada vez que le formulamos alguna pregunta. El corpus que usa la segunda versión disponible desde el 2012 alcanza los 20 millones de libros (casi un 10% de todos los libros publicados en todas épocas).
Nunca antes la humanidad fue capaz de procesar semejante elefantismo bibliográfico.
Culturonomía para todos
En diciembre de 2010, Google lanzó una herramienta en línea para el análisis de la historia de la lengua y la cultura que explora el gigantesco corpus de textos históricos escaneados y digitalizados como parte del proyecto de
Google Books. Lo llamaron
Ngram Viewer, y fue presentado al mismo tiempo con un
paper en la revista Science (que luego sería revisitado en una breve, intensa y entretenida
conferencia TED) donde los autores anunciaban un neologismo que refería al incipiente campo de investigación en el que el nuevo artefacto se inscribiría: «
culturomics«.
Allí lo definían como la aplicación de la recopilación de datos y el análisis de alto rendimiento para el estudio de la cultura humana, extendiendo los límites de la investigación cuantitativa rigurosa a una amplia gama de nuevos fenómenos que abarcan las ciencias sociales y las humanidades.
Siguiendo esta definición N-Gram fue pensado en sus inicios para ser puesta al servicio de lingüistas, lexicógrafos e historiadores para el análisis de la historia de la lengua y la cultura. Una herramienta de investigación para especialistas.
Lo que no se imaginaron era que su popularidad se extendiera entre los usuarios casuales como lo hizo. Según los datos ofrecidos por Google más de 45 millones de gráficos de comparación de palabras fueron creados tan solo en sus primeros 22 meses de vida.
Incorporando operadores a nuestras búsquedas
Hace un tiempo
nos sorprendíamos de lo que podíamos hacer con N-gram al utilizarlo como generador de indicios históricos en el ámbito de la ciencia. En ese entonces quedamos entusiasmadísimos de lo que lográbamos con tan poco y
la potencia que esta aplicación tendría abriéndola al juego de la imaginación de un colectivo de personas ocupadas en sacarle un provecho creativo.
Lo que no sabíamos entonces era que como en toda buena interfaz para los tiempos de barbarie que corren (Baricco, 2008) la puerta de entrada es sencilla pero la invitación a desarrollar un uso más complejo está siempre abierta.
Para esto N-gram ofrece una serie de operadores, elementos que se incorporan a nuestras estrategias de búsqueda permitiendo complejizarlas y mejorarlas, que expanden notablemente sus posibilidades interrogatorias. Estos se organizan en tres categorías: tags sintácticos, corpus y matemáticos.
Tags sintácticos
Todas las palabras en el Corpus Ngram han sido etiquetadas de acuerdo al modo en que estas forman parte de una oración, tales etiquetas (tags) a su vez también pueden incluirse en la búsqueda (aún no está funcionando para el corpus en español, pero de seguro no se demorarán mucho en ponerlo a disposición).
Por ejemplo, se pueden indagar los usos de un término como Verbo (término_VERB) y al mismo tiempo como sustantivo (término_NOUN).
Veamos un ejemplo.

En este caso hemos pedido que rastree en el corpus en inglés las veces en que la palabra “orange” (la cual puede designar un atributo de color o referirse al nombre de una fruta) aparece utilizada como sustantivo por un lado y como adjetivo por otro.
Incorporemos un operador sintáctico más a nuestro ejemplo y al caso de la búsqueda de “Orange” como sustantivo vamos a agregarle un término que nos devuelva los resultados respecto de la cantidad de veces que este nombre aparece precedido por un artículo. De manera que tendremos tres resultados (líneas) a comparar: _ADJ_ orange (orange como adjetivo), _NOUN orange (orange como sustantivo), y _DET_ _NOUN_ orange (orange como sustantivo precedido de un artículo).

Lo interesante de este último ejemplo es la inserción de un campo variable ya que _DET_ no se refiere ningún artículo en particular sino a cualquiera de ellos que se inserten en una oración antecediendo a la palabra «orange» utilizada como sustantivo.
Otros de los operadores sintácticos, _START_ y _END_, nos permiten señalar que la búsqueda se ciña a los casos en que los términos rastreados se comporten como comienzo o cierre de oración.
Los operadores sintácticos no se agotan en estos ejemplos sino que son varios más como se muestra en la siguiente tabla.
Corpus
Los operadores de corpus nos permiten realizar un ejercicio muy interesante que ensancha notablemente las posibilidades de la aplicación como lo es el contrastar en un sólo gráfico la búsqueda de un mismo o de diferentes términos en corpus de distintos idiomas.
En el ejemplo de arriba vemos cómo se comportan las menciones del nombre de Michel Foucault en francés, español, alemán en ingles simultáneamente.
Operadores matemáticos
Por último encontramos los operadores matemáticos que probablemente sean los que realizan la maniobra más extraña que se nos hubiera ocurrido jamás como el aplicar operaciones aritméticas a las palabras.
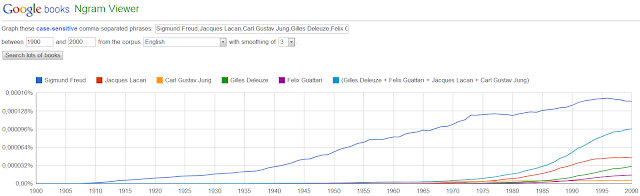
En este primer caso vamos ver cómo funciona el operador suma.
En el gráfico de arriba vemos como las citas de Sigmund Freud superan ampliamente a la de otros personajes ligados al análisis de la psiquis humana a punto tal que ni las suma de todos ellos logran siquiera igualar a las del padre del psicoanálisis.
En el caso del operador resta funciona siguiendo la misma lógica que el operador suma pero aplicando una substracción del volumen de resultados del término de la derecha al volumen de resultados del término de la izquierda.
El caso de la multiplicación (el último de los operadores que revisaremos en este post) resulta muy útil al momento de confrontar el comportamiento de curvas de resultados cuyos volúmenes son muy disímiles. En ese caso, al volumen más pequeño se le aplica un multiplicador como se muestra en el ejemplo de abajo en el que se comparan el volumen de resultados para la palabra violín y la palabra ukelele. Esta última con un multiplicador de 100.
Finalmente y con la idea de que experimentemos con esta simple pero potentísima herramienta diseñamos un
tutorial interactivo que dejamos a disposición en la imagen que sigue.
Los invitamos a que compartan los resultados de sus experimentos en los comentarios de este post. Sigamos aprendiendo!!!
*Nota del editor: Este post fue publicado originalmente en
Contrapunto





Comentarios
Humanidades Dixitais | Annotary
[…] Publisher More from A Petapouca: Miscellaneous Cinema de vampiros Sort Share http://www.catedradatos.com.ar 4 minutes […]
Culturonomía para todos. Aprendiendo a u...
[…] En diciembre de 2010, Google lanzó una herramienta en línea para el análisis de la historia de la lengua y la cultura que explora el gigantesco corpus de textos históricos escaneados y digitalizados como parte del proyecto de Google Books. Lo llamaron Ngram Viewer, y fue presentado al mismo tiempo con un paper en la revista Science (que luego sería revisitado en una breve, intensa y entretenida conferencia TED) donde los autores anunciaban un neologismo que refería al incipiente campo de investigación en el que el nuevo artefacto se inscribiría: “culturomics“. […]
Diseño lúdico de actividades. Herramientas que apuestan a la resiliencia
[…] exigentes) para resistir o al menos movernos mejor frente al embate. Así fue que arrancamos con N-gram una herramienta con un nivel de dificultad inicial mínimo incluso para quienes nunca habían […]
Mariela Melli - Comision 11
La importancia de englobar miles de palabras en una imagen es poder ver las cosas desde otro punto de vista y de una manera mas simple sin perdernos el contenido que las sustenta.
Eso me recuerda a los retratos tipográficos donde se utilizan palabras para formar rostros. Las palabras van siempre en relación con la imagen final. Asi por ejemplo los rolling stones formados por las letras de sus canciones http://photos3.pix.ie/A2/71/A2716FC41C4E442789D9E2524D9E4613-0000330897-0002661099-00800L-8E6893C821674EC6B02A5586C6D1F89C.jpg
Culturonomía para todos. Aprendiendo a u...
[…] Por Aníbal Rossi Una imagen que vale 500.00 millones de palabras* Alguna vez Séneca supo decir que el andar entre muchos libros disipaba el espíritu. Claro que sus discursos cobraban vida a partir de una positividad muy diferente a la… […]